- Homepage
- >
- Search Page
- > News
- >
Software Co-Design Actions in European Flagship HPC Codes


Earlier this summer, FocusCoE gathered with the European HPC Centres of Excellence at ISC High Performance (ISC) 2022 for our first Workshop on Software Co-Design Actions in European Flagship HPC Codes. Organised jointly by FocusCoE, SiPearl, Arm Ltd and NVIDIA, this workshop focused specifically on software co-design actions applied to production-grade community-wide European flagship HPC applications. Scientists representing MaX, EoCoE, POP, BioExcel, TREX, and RAISE Centres of Excellence shared their experiences and lessons learnt in software co-design, which can now also be viewed in the presentations below.
Co-design with Proxy-Apps: A match made in heaven?
Jens Domke (RIKEN R-CCS) [Invited Speaker]
Performance Assessment and Energy Efficiency of MaX Codes
Daniele Cesarini (CINECA, MaX)
Alya – computational fluid dynamics on exascale GPU hardware for the wind community
Herbert Owen (BSC, EoCoE)
Resources for co-design in the POP CoE
Xavier Teruel (BSC, POP)
HPC Co-Design in GROMACS
Szilárd Páll (KTH, BioExcel)
Co-Designing a high performance and portable library (QMCKL): one of the major challenges addressed by TREX CoE
William Jalby (UVSQ, TREX)
Performance analysis and code optimizations for distributed training of autoencoders
Rakesh Sarma (JSC, RAISE)
FocusCoE Completes its Mission to Support the Consolidation of CoEs’ Role in the EU HPC Ecosystem
As of 31 March, 2022, the EU-funded coordination and support action FocusCoE has successfully completed its project activities, which have supported the European High-Performance Computing Centres of Excellence (HPC CoEs) by enhancing their interaction with industry, facilitating inter HPC CoE collaboration, and strengthening their position in the European HPC ecosystem. Moreover, FocusCoE broadened the promotion of EU HPC CoEs and their relevance inside and outside of the EU HPC ecosystem through a variety of compiled materials on HPC CoE activities including some for a non-technical audience. Lastly, FocusCoE created the HPC CoE Council (HPC3) and the central hub for CoE resources at hpccoe.eu, which will both continue supporting ongoing and future HPC CoEs to coordinate their efforts and reaching new stakeholders in European industry, research, and public administration.
Although the originally planned methods for supporting CoEs had to be modified due to the Covid-19 pandemic, the major objectives have borne fruit – realizing a great deal of cross-CoE collaboration and interaction. As an example, FocusCoE coordinated concerted outreach to industry by identifying and organizing participation in 11 sectorial events related to work being done by HPC CoEs. In all, the EU HPC CoEs are active in the domains of energy, computational (bio-)medicine, material science, engineering, computational chemistry, earth system modelling, and global challenges. FocusCoE also hosted workshops for the HPC CoEs addressing various aspects related to business development and best practices for industry outreach. Additionally, 6 CoE directed training events were organized around EU HPC training needs and best practices while trainings offered by HPC CoEs were promoted via a centralized CoE training registry. The Covid-19 related shift from in-person to virtual activities in the middle of the project also prompted FocusCoE to create template materials and guides for both in-person and virtual events, which will support current and upcoming EU HPC CoEs in a greater variety of activities in the future. Overall, these activities worked to increase awareness of and competence in HPC applications across the EU HPC ecosystem to ensure a robust user base for the HPC CoE software that will be used on the next generation of HPC machines.
“While each individual CoE has had a primary objective to prepare their community’s applications for Exascale computing,” says Project Coordinator Guy Lonsdale, “we have seen many benefits arising from cross-CoE collaborations and presenting a common strategic position with regards to the development of the EuroHPC ecosystem. I am pleased to see that FocusCoE played a key role in that.”
Public awareness and understanding of high-performance computing were strengthened through the creation of a variety of FocusCoE resources. Based on HPC CoE activities, FocusCoE selected success stories and use cases to illustrate the breadth of HPC CoE work to audiences unfamiliar with the EU HPC CoEs. Additionally, FocusCoE consolidated various HPC CoE contributions to addressing societal challenges for a non-technical audience. An article published in the first year of the Covid-19 pandemic explained how HPC CoEs working in everything from biomolecular modelling to materials science were helping combat the pandemic. More recently, an article on how HPC CoEs are helping to mitigate the consequences of climate change provided a non-technical explanation of work in novel materials for carbon capture, alternative sources of energy, and computer modelling to track urban air pollution.
The important role played by the HPC CoEs is illustrated by their continuation within the latest EuroHPC Joint Undertaking work programme. Accordingly, strategic collaboration among HPC CoEs will continue to be supported by FocusCoE activity through its creation of the HPC CoE Council, which is maintaining its independent operation after the end of the project. The unique one-stop-shop central hub of CoE information will also endure on the hpccoe.eu website. Going forward, many of the CoEs have the potential to contribute to the European objective of reducing global dependencies through their HPC-enabled tools supporting the development of new technologies and solutions, for example in the areas of renewable energy and new materials.
Mitigating the Impacts of Climate Change: How EU HPC Centres of Excellence Are Meeting the Challenge
“The past seven years are on track to be the seven warmest on record,” according to the World Meteorological Organization. Furthermore, the earth is already experiencing the extreme weather consequences of a warmer planet in the forms of record snow in Madrid, record flooding in Germany and record wildfires in Greece in 2021 alone. Although EU HPC Centres of Excellence (CoEs) help to address current societal challenges like the Covid-19 pandemic, you might wonder, what can the EU HPC CoEs do about climate change? For some CoEs, the answer is fairly obvious. However just as with Covid-19, the contributions of other CoEs may surprise you!
Given that rates of extreme weather events are already increasing, what can EU HPC CoEs do to help today? The Centre of Excellence in Simulation of Weather and Climate in Europe (ESiWACE) is optimizing weather and climate simulations for the latest HPC systems to be fast and accurate enough to predict specific extreme weather events. These increasingly detailed climate models have the capacity to help policy makers make more informed decisions by “forecasting” each decision’s simulated long-term consequences, ultimately saving lives. Beyond this software development, ESiWACE also supports the proliferation of these more powerful simulations through training events, large scale use case collaborations, and direct software support opportunities for related projects.
Even excepting extreme weather and long-term consequences, though, climate change has other negative impacts on daily life. For example the World Health Organization states that air pollution increases rates of “stroke, heart disease, lung cancer, and both chronic and acute respiratory diseases, including asthma.” The HPC and Big Data Technologies for Global Systems Centre of Excellence (HiDALGO) exists to provide the computational and data analytic environment needed to tackle global problems on this scale. Their Urban Air Pollution Pilot, for example, has the capacity to forecast air pollution levels down to two meters based on traffic patterns and 3D geographical information about a city. Armed with this information and the ability to virtually test mitigations, policy makers are then empowered to make more informed and effective decisions, just as in the case of HiDALGO’s Covid-19 modelling.
What does MAterials design at the eXascale have to do with climate change? Among other things, MaX is dramatically speeding up the search for materials that make more efficient, safer, and smaller lithium ion batteries: a field of study that has had little success despite decades of searching. The otherwise human intensive process of finding new candidate materials moves exponentially faster when conducted computationally on HPC systems. Using HPC also ensures that the human researchers can focus their experiments on only the most promising material candidates.
Continuing with the theme of materials discovery, did you know that it is possible to “capture” CO2 from the atmosphere? We already have the technology to take this greenhouse gas out of our air and put it back into materials that keep it from further warming the planet. These materials could even be a new source of fuel almost like a man-made, renewable oil. The reason this isn’t yet part of the solution to climate change is that it is too slow. In answer, the Novel Materials Discovery Centre of Excellence (NoMaD CoE) is working on finding catalysts to speed up the process of carbon capture. Their recent success story about a publication in Nature discusses how they have used HPC and AI to identify the “genes” of materials that could make efficient carbon-capture catalysts. In our race against the limited amount of time we have to prevent the worst impacts of climate change, the kind of HPC facilitated efficiency boost experienced by MaX and NoMaD could be critical.
Once one considers the need of efficiency, it starts to become clear what the Centre of Excellence for engineering applications EXCELLERAT might be able to offer. Like all of the EU HPC CoEs, EXCELLERAT is working to prepare software to run on the next generation of supercomputers. This preparation is vital because the computers will use a mixture of processor types and be organized in a variety of architectures. Although this variety makes the machines themselves more flexible and powerful, it also demands increased flexibility from the software that runs on them. For example, the software will need the ability to dynamically change how work is distributed among processors depending on what kind and how many a specific supercomputer has. Without this ability, the software will run at the same speed no matter how big, fast, or powerful the computer is: as if it only knows how to work with a team of 5 despite having a team of 20. Hence, EXCELLERAT is preparing engineering simulation software to adapt to working efficiently on any given machine. This kind of simulation software is making it possible to more rapidly design new airplanes for characteristics like a shape that has less drag/better fuel efficiency, less sound pollution, and easier recycling of materials when the plane is too old to use.
Another CoE using HPC efficiency to make our world more sustainable is the Centre of Excellence for Combustion (CoEC). Focused exclusively on combustion simulation, they are working to discover new non-carbon or low-carbon fuels and more sustainable ways of burning them. Until now, the primary barrier to this kind of research has been the computing limitations of HPC systems, which could not support realistically detailed simulations. Only with the capacity of the latest and future machines will researchers finally be able to run simulations accurate enough for practical advances.
Outside of the pursuit for more sustainable combustion, the Energy Oriented Centre of Excellence (EoCoE) is boosting the efficiency of entirely different energy sources. In the realm of Wind for Energy, their simulations designed for the latest HPC systems have boosted the size of simulated wind farms from 5 to 40 square kilometres, which allows researchers and industry to far better understand the impact of land terrain and wind turbine placement. They are also working outside of established wind energy technology to help design an entirely new kind of wind turbine.
In work also related to solar energy, the EoCoE Materials for Energy group is finding new materials to improve the efficiency of solar cells as well as separately working on materials to harvest energy from the mixture of salt and fresh water in estuaries. Meanwhile, the Water for Energy group is improving the modelling of ground water movement to enable more efficient positioning of geothermal wells and the Fusion for Energy group is working to improve the accuracy of models to predict fusion energy output.
EoCoE is also developing simulations to support Meteorology for Energy including the ability to predict wind and solar power capacity in Europe. Unlike our normal daily forecast, energy forecasts need to calculate the impact of fog or cloud thickness on solar cells and wind fluctuations caused by extreme temperature shifts or storms on wind turbines. Without this more advanced form of weather forecasting, it is unfeasible for these renewable but variable energy sources to make up a large amount of the power supplied to our fluctuation sensitive grids. Before we are able to rely on wind and solar power, it will be essential to predict renewable energy output in time to make changes or supplement with alternate energy sources, especially in light of the previously mentioned increase in extreme weather events.
Suffice it to say that climate change poses a variety of enormous challenges. The above describes only some of the work EU HPC CoEs are already doing and none of what they may be able to do in the future! For instance, HiDALGO also has a migration modelling program currently designed to help policy makers divert resources most effectively to migrations caused by conflict. However, similar principles could theoretically be employed in combination with weather modelling like that done by ESiWACE to create a climate migration model. Where expertise meets collaboration, the possibilities are endless! Make sure to follow the links above and our social media handles below to stay up to date on EU HPC CoE activities.
FocusCoE at EuroHPC Summit Week 2022
With the support of the FocusCoE project, almost all European HPC Centres of Excellence (CoEs) participated once again in the EuroHPC Summit Week (EHPCSW) this year in Paris, France: the first EHPCSW in person since 2019’s event in Poland. Hosted by the French HPC agency Grand équipement national de calcul intensif (GENCI), the conference was organised by Partnership for Advanced Computing in Europe (PRACE), the European Technology Platform for High-Performance Computing (ETP4HPC), The EuroHPC Joint Undertaking (EuroHPC JU), and the European Commission (EC).As usual, this year’s event gathered the main European HPC stakeholders from technology suppliers and HPC infrastructures to scientific and industrial HPC users in Europe.

At the workshop on the European HPC ecosystem on Tuesday 22 March at 14:45, where the diversity of the ecosystem was presented around the Infrastructure, Applications, and Technology pillars, project coordinator Dr. Guy Lonsdale from Scapos talked about FocusCoE and the CoEs’ common goal.
Later that day from 16:30 until 18:00h, the FocusCoE project hosted a session titled “European HPC CoEs: perspectives for a healthy HPC application eco-system and Exascale” involving most of the EU CoEs. The session discussed the key role of CoEs in the EuroHPC application pillar, focussing on their impact for building a vibrant, healthy HPC application eco-system and on perspectives for Exascale applications. As described by Dr. Andreas Wierse on behalf of EXCELLERAT, “The development is continuous. To prepare companies to make good use of this technology, it’s important to start early. Our task is to ensure continuity from using small systems up to the Exascale, regardless of whether the user comes from a big company or from an SME”.
Keen interest in the agenda was also demonstrated by attendees from HPC related academia and industry filling the hall to standing room only. In light of the call for new EU HPC Centres of Excellence and the increasing return to in-person events like EHPCSW, the high interest in preparing the EU for Exascale has a bright future.
AI Café: How can HPC technologies help AI
On March 17th, FocusCoE participated in a live AI for Media Web Café alongside the three Centres of Excellence: RAISE, CoEC, and HiDALGO. The virtual session brought together the CoEs working in AI sectors to explain how HPC technologies can help AI. In all, over 40 participants from industry and research joined the hour and a half café.
Starting off the presentations, Xavier Salazar introduced FocusCoE and the resources available at the “one stop shop” of our website such as technological offerings. Here, anyone from industry or research who wants to learn more can also read up on use cases, search available codes and software packages, and link directly to the CoEs of interest.
Next, the CoEs presented several case studies on how they are using AI in combination with HPC technologies to solve real-life problems. Although each CoE’s application of AI differed, some common themes emerged in answer to the question, “How can HPC help AI?” Firstly, AI is now benefitting from the increasing availability of large and even “big” data sets but often can’t use them in their entirety due to excessive processing time. This is by far the clearest example of how HPC can help. In a use case described by Andreas Lintermann on behalf of CoE RAISE, a dataset that was estimated to take over 300 hours to process using 4 GPUs was modified to run on HPC systems theoretically as large as 2000 GPUs in as little as 45 minutes! With the ability to more quickly train AI models using more data, it is also possible to increase the accuracy of the resulting models or surrogates. In turn, building more accurate surrogates speeds up the ability to run accurate simulations since one no longer needs to build the simulation models by hand.
Using AI to build data model surrogates also has benefits for data privacy, as discussed by Christoph Schweimer from HiDALGO. When modelling how messages spread across social media, researchers initially had to build social network graphs manually from data harvested from real social media users, whose privacy had to be strictly protected. However, with HPC computing resources, HiDALGO researchers were able to use those real graphs to train AI to build simulated social network graphs instead. These simulated graphs share the same characteristics of real graphs but require far less time to create and don’t rely on any real-user data: thus holding no privacy risks to users.
The experience gained through these use cases has naturally brought several opportunities and challenges to light, which were also discussed over the course of the program. For instance, Temistocle Grenga from CoEC highlighted the existing bottleneck of moving data between different types of processors (CPU and GPU, as examples).
Lastly, CoEs summarized the numerous resources in terms of services and training opportunities they provide to help AI experts learn to exploit the benefits of HPC. As an immediate example, CoEC will participate this week in South-East Europe Combustion Spring School 2022. For ongoing information on training like this, make sure to bookmark our training calendar, which shows events from all the EU HPC CoEs.
For the full recording of this event, check out the video below!
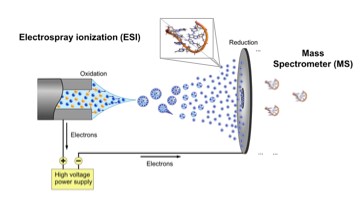
BioExcel: Electronic Interaction Phenomena: Proton Dynamics and Fluorescent Proteins
Short description
Fluorescent proteins are the backbone of many high-resolution microscopy techniques. To improve resolution, these proteins may require optimization for the specific conditions under which the imaging is carried out. While directed evolution works well if a single property needs to be optimized, optimizing multiple properties simultaneously remains challenging. Furthermore, this approach provides only limited physical insights into the process that is the target of the optimization. In contrast, computational chemistry provides a route to obtain such insights from first principles, but because such calculations typically require a high level of expertise, automatic workflows for in silico screening of fluorescent proteins are not yet generally available. To overcome this limitation we developed a user-friendly workflow for automatically computing the most relevant properties of fluorescent protein mutants based on established atomistic molecular dynamics models.
Results & Achievements
Objectives
FocusCoE Hosts Intel OneAPI Workshop for the EU HPC CoEs
On March 2, 2022 FocusCoE hosted Intel for a workshop introducing the oneAPI development environment. In all, over 40 researchers representing the EU HPC Centres of Excellence (CoEs)were able to attend the single day workshop to gain an overview of OneAPI. The 8 presenters from Intel gave presentations through the day covering the OneAPI vision, design, toolkits, a use case with GROMACS (which is already used by some of the EU HPC CoEs), and specific tools for migration and debugging.
Launched in 2019, the Intel OneAPI cross-industry, open, standards-based unified programming model is being designed to deliver a common developer experience across accelerator architectures. With the time saved designing for specific accelerators, OneAPI is intended to enable faster application performance, more productivity, and greater innovation. As summarized on Intel’s OneAPI website, “Apply your skills to the next innovation, and not to rewriting software for the next hardware platform.” Given the work that EU HPC CoEs are currently doing to optimise codes for Exascale HPC systems, any tools that make this process faster and more efficient can only boost CoEs capacity for innovation and preparedness for future heterogeneous systems.
The OneAPI industry initiative is also encouraging collaboration on the oneAPI specification and compatible oneAPI implementations. To that end, Intel is investing time and expertise into events like this workshop to give researchers the knowledge they need not only to use but help improve OneAPI. The presenters then also make themselves available after the workshop to answer questions from attendees on an ongoing basis. Throughout our event, participants were continuously able to ask questions and get real-time answers as well as offers for further support from software architects, technical consulting engineers, and the researcher who presented a use case. Lastly, the full video and slides from presentations are available below for any CoEs who were unable to attend or would like a second look at the detailed presentations.







MEDICA Trade Fair 2021
On 17 November, 2021 Mariano Vasquez represented CompBioMed and PerMed CoE Centres of Excellence in an expert panel at the MEDICA Trade Fair’s Health IT Forum. Despite the challenges of the ongoing COVID-19 pandemic, the leading medical sector conference covering innovations in outpatient and clinical care was able to offer a 2021 hybrid conference with in-person attendance in Düsseldorf alongside virtual attendance from anywhere in the world. The Biomedical Experts Panel was comprised of professionals from imaging, data mining, data sharing, artificial intelligence, and robotics. Overall, they broadly discussed why IT solutions aren’t yet widely used in clinical settings and what the major barriers to wider adoption are.
In addition to the unanimously cited barrier of awareness, Mariano Vasquez explained how CompBioMed and PerMed Centres of Excellence are overcoming the specific difficulties in making clinicians aware of HPC’s potential in healthcare. “Work directly with doctors and let them take the reins of our research. When the clinicians are leading the way, they develop awareness of HPC and AI potential.” He continued by highlighting that, “in the CoEs we have resources to create a pipeline for using these tools,” Such as CompBioMed including computational biomedicine in curriculums for medical students.
Beyond awareness, all panel members indicated the further need for support from regulatory, legal, and clinical leadership stakeholders particularly in the case of the newest technologies like artificial intelligence. In the case of tools running off-site on HPC systems Mariano emphasized, “If you get the regulatory bodies saying the tools are ok, then the doctors and our customers like biomedical companies […]can start using the tools.”
Once an IT solution has awareness and hopefully broad stakeholder support, however, the next biggest challenge is training. In particular, Mariano highlighted how training for both clinicians and IT researchers is vital to building a common language for communication about IT solutions. “It’s like I have a hammer and the doctor has a nail and we need to link them. If the doctor’s never seen a hammer, he can’t know what to do with it even if the nail is in front of his nose.” When a researcher with perhaps a physics background shows something to a clinician, it is essential that the researcher understands the clinical problem, that both researcher and clinician can communicate about the solution in clinical terms, and that the clinician can provide feedback on the technology’s use.
In conclusion, all panel members made a call to unified action. As summarized by Mariano, “This is not science fiction, it is science […]This is something at hand now.” IT solutions exist but need support across stakeholder groups from researchers, to clinicians, through IT departments, and including leadership.
To the audience of health care professionals, Mariano encouraged, “Contact us. Don’t be shy!”
For more on the panel, log on and watch via the MEDICA On Demand Livestreams portal until 31 March, 2022.
For more on activities of the European Centres of Excellence such as CompBioMed and PerMed CoE, subscribe to our newsletter!
GPU Bootcamps and Hackathons 2022
GPU acceleration is a key feature of many modern supercomputers. Therefore, a series of GPU hackathons and bootcamps, many of which are organized by partner institutions of European Centres of Excellence for High-Performance Computing and National Competence Centres, will take place throughout Europe again this year. The following (and many more) hackathons and bootcamps will be hosted in a hybrid or purely digital format:
- NVIDIA/ LRZ AI for Science Bootcamp 2022 in February: This Bootcamp is co-organised by LRZ, HLRS, JSC, OpenACC.org and NVIDIA for EuroCC@GCS, the German National Competence Centre for High-Performance Computing
NVIDIA/ LRZ N-Ways To GPU Programming Bootcamp 2022 in March: This Bootcamp is co-organised by LRZ, HLRS, JSC, OpenACC.org and NVIDIA for EuroCC@GCS, the German National Competence Centre for High-Performance Computing
- ENCCS OpenACC Bootcamp 2022 in March
- Helmholtz GPU Hackathon 2022 in March
The hackathons and bootcamps are multi-day intensive hands-on events designed to help scientists, researchers, and developers to accelerate and optimize their applications for GPUs using libraries, OpenACC, CUDA and other tools by pairing participants with dedicated mentors experienced in GPU programming and development.
Representing distinguished scholars and pre-eminent institutions around the world, these teams of mentors and attendees work together to realize performance gains and speed-ups by taking advantage of parallel programming on GPUs.
Applications can be submitted at www.gpuhackathons.org.

NAFEMS 2021 World Congress
In the last week of October, nearly 950 participants from industry and academia gathered for the International Association for the Engineering Modeling, Analysis and Simulation 2021 World Congress (NWC21). Originally planned as a hybrid event, all programming unfortunately had to be shifted online. However, this year’s Congress was also held in conjunction with the 5th International SPDM (Simulation Process & Data Management) Conference, the NAFEMS Multiphysics Simulation Conference, and a dedicated Automotive CAE Symposium.
Unsurprisingly, the online and truly globally accessible conference also attracted a record breaking over 550 abstract submissions. Among those accepted, EXCELLERAT and POP Centres of Excellence gave five 20-minute presentations ranging from improving airplane simulations to improving the new user HPC experience. Throughout the week Monday – Thursday, representatives from EXCELLERAT, POP, and FocusCoE also presented more general videos and materials on current projects at their 3D interactive virtual booth. This year, we welcomed over 100 visitors to the booth, and the completely new NAFEMS World of Engineering Simulation 3D experience had up to 600 conference participants strolling the virtual exhibition hall at any given time.
Beginning on Tuesday the 26th, Ricard Borrell presented Airplane Simulations on Heterogeneous Pre-Exascale Architectures on behalf of EXCELLERAT CoE. He used the example of improved airplane aerodynamics simulations to discuss how their Alya code is preparing researchers to fully utilise the next generation of Exascale HPC systems and their heterogeneous hardware architectures. Without codes optimised like Alya, current HPC codes wouldn’t be capable of running in parallel on different types of processors to the extent that new Exascale systems will require. Thus, they would use only a fraction of the speed and processing power available at Exascale.
Continuing in this theme, Amgad Dessoky presented an overview of how the EXCELLERAT Centre of Excellence is Paving the Way for the Development to Exascale Multiphysics Simulations including the 6 computational codes they are optimizing for Exascale: Nek5000, Alya, AVBP, TPLS, FEniCS, and Coda. Using automotive, aerospace, energy, and manufacturing industrial sector use cases, he described the common challenges for developers and potential users of HPC Exascale applications. Participants were also invited to discuss how EXCELLERAT can best support the needs and required competencies of the Multiphysics simulation community going forward.
One of these required competencies is the ability to understand and improve the performance bottlenecks of parallel codes. In answer, Federico Panichi presented a talk titled Improving the Performance of Engineering Codes on behalf of the Performance Optimisation and Productivity (POP) Centre of Excellence. The set of hierarchical metrics forming the POP performance assessment methodology cuts out the time-consuming trial and error process of code optimisation by identifying issues such as memory bottlenecks, communication inefficiencies, and load imbalances. He demonstrated with the example of optimised engineering codes how POP services could enable any EU or UK academic or commercial organisation to speed up time to solution, solve larger, more challenging problems or reduce compute costs free of charge.
On Wednesday the 27th, presentations continued with Christian Gscheidle representing EXCELLERAT and A Flexible and Efficient In-situ Data Analysis Framework for CFD Simulations. Because Computational Fluid Dynamics (CFD) simulations Increasingly produce far more data than they can save in real time, researchers often see final analysis results and lose the intermediate data. It also means that they must wait until the full simulation runs before being able to make any improvements. In contrast, he presented the EXCELLERAT tool that uses machine learning to perform in-situ analyses on data produced during large-scale simulations in real time so that researchers can see intermediate results and early trends. Using this tool, an example HVAC duct from an automotive set up use case showed a reduced compute time because researchers were able to abort simulations with unwanted behaviour.
Wrapping up the presentations, Janik Schüssler presented Creating Connections: Enabling High Performance Computing for Industry through a Data Exchange & Workflow Platform on behalf of EXCELLERAT. Continuing in the theme of the previous presentations, this tool addresses the needs and competencies of current and potential HPC users, albeit in a slightly different way. As discussed in the talk, where other tools or trainings work to develop HPC competencies in the user, this prototype platform would bring HPC to the user both in terms of competencies and location. The user would be able to remotely access clusters (currently both HLRS Hawk and Vulcan) from anywhere using an authorised device. Additionally, they would be able to run simulations in the web front end without any command line interactions, which can have a steep learning curve for new users. Ultimately, the savings in logistical coordination, travel, and training time would drastically lower the entry barrier to HPC use.
If you’re interested in following how EXCELLERAT, POP, and all the European HPC Centres of Excellence are preparing us for Exascale and improving the HPC user experience, sign up for our newsletters:
Focus CoE Newsletter (for coverage of all European HPC CoEs)