





EoCoE: Performance Portability on HPC Accelerator Architectures with Modern Techniques: The ParFlow Blueprint
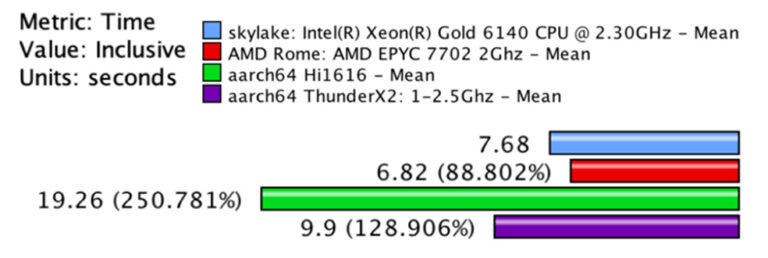
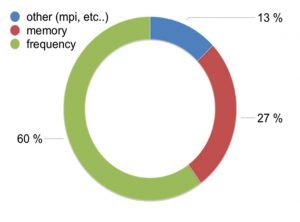
Performance Portability on HPC Accelerator Architectures with Modern Techniques: The ParFlow Blueprint A Use Case by Short description Rapidly changing heterogeneous supercomputer architectures pose a great challenge to many scientific
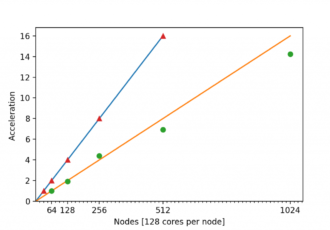
Excellerat: Bringing industrial end-users to Exascale computing: An industrial level combustion design tool on 128K core
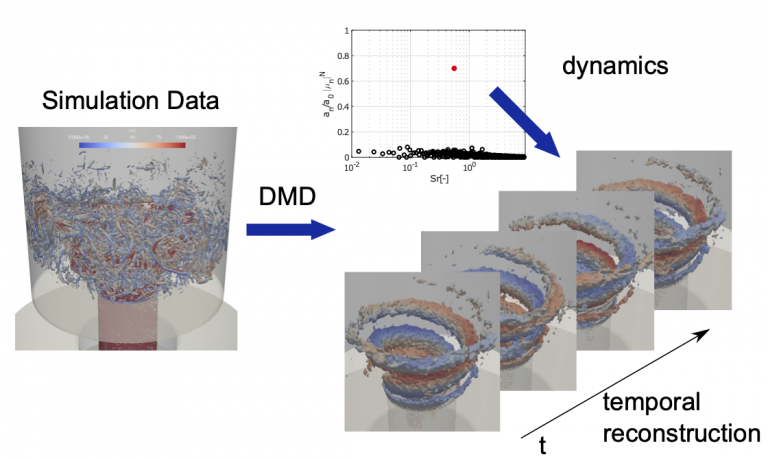
Excellerat Success Story: Bringing industrial end-users to Exascale computing: An industrial level combustion design tool on 128K cores CoE involved: Strong scaling for turbulent channel (tri) and rocket engine simulations
Excellerat: Enabling High Performance Computing for Industry through a Data Exchange & Workflow Portal
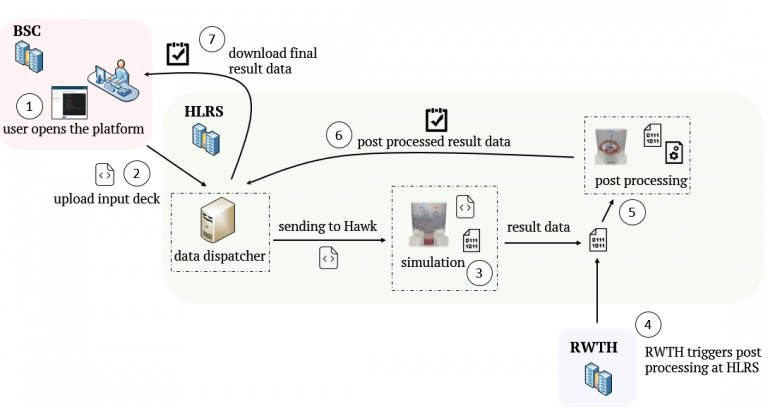
Excellerat Success Story: Enabling High Performance Computing for Industry through a Data Exchange & Workflow Portal CoE involved: Success story # Highlights: Keywords: Data Transfer Data Management Data Reduction Automatisation,
Submit your proposal to the second FF4EuroHPC Open Call to benefit from the use of advanced HPC services
The FF4EuroHPC project started at the beginning of September 2020. As a part of the EuroHPC Joint Undertaking, under the auspices of the European Commission’s Horizon 2020 program, has been awarded
CoEs at Teratec Forum 2021 and ISC21
With the support of FocusCoE, a number of HPC CoEs will give short presentations at the virtual PRACE booth in the following two HPC-related events: Teratec Forum 2021 and ISC2021

FocusCoE organizes two workshops at EHPCSW21
With the support of the FocusCoE project, a number of the HPC CoE participated in the first online edition of the EuroHPC Summit Week 2021 (EHPCSW21) in the context of
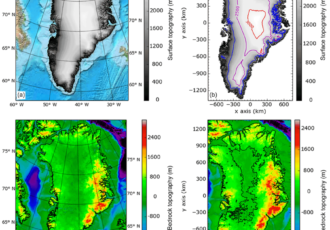
ESiWACE: OBLIMAP ice sheet model coupler parallelization and optimization
The goal of this use case is to reduce the memory footprint of the code by improving its distribution over parallel tasks, and to resolve the I/O bottleneck by implementing parallel reading and writing.
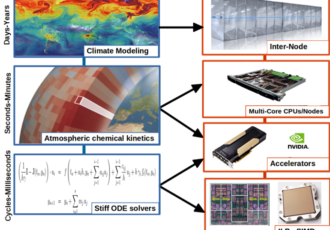
ESiWACE: GPU Optimizations for Atmospheric Chemical Kinetics
The goal of this use case is to reduce the memory footprint of the EMAC code in the GPU device, thereby allowing more MPI tasks to be run concurrently on the same hardware.

List of Innovations by CoEs spotted by Innovation Radar
A list of innovations by the HPC Centres of Excellence, as spotted by the EU innovation radar
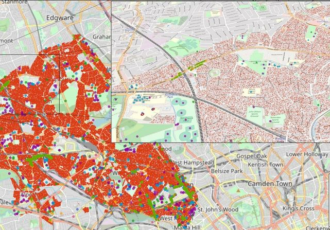
HiDALGO: Assisting decision makers to solve Global Challenges with HPC applications – Covid-19 modelling
The success story describes how HiDALGO supports the UK National Health Service with tools to detect, predict and even prevent the virus spread behaviour in the current pandemic situation.
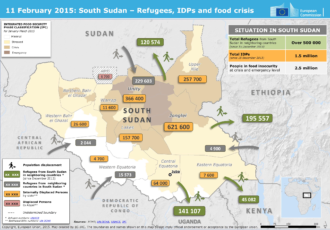
HiDALGO: Assisting decision makers to solve Global Challenges with HPC applications – Migration issues
The success story shows how HiDALGO supports NGOs with providing more accurate estimations on people flows and even destinations to send the appropriate amount of help to the right place.
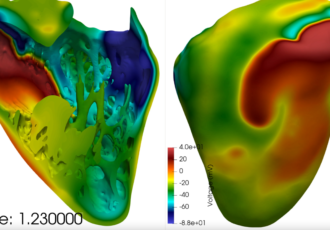
CompBioMed: In silico trials for effects of COVID-19 drugs on heart
The use case assesses the impact of certain COVID-19 drugs on a human heart population
Four HPC CoES (ChEESE, EoCoE, ESiWACE, POP) will be present at the exhibition of the first digital edition of the Forum Teratec 2020 in order to present their results in a two-days virtual exhibition on October 13-14. Do not miss the opportunity to have a look at their virtual booths!
Due to the Covid-19 pandemic, Forum Teratec 2020 goes virtual and offers the possibility to all HPC-related initiatives to present their results online. Also CHEESE, EoCoE, ESIWACE and POP will show their results via the internet.
The Teratec Forum 2020 brings together the best international experts in HPC, Simulation and Big Data for its next edition taking place on 13-14 October 2020. During these two days, a virtual exhibition environment will bring together a large number of technology companies presenting their latest innovations in the fields of Simulation, HPC, Big Data and AI. The digital platform will allow exhibitors and participants to share B2B meeting plans as well as product and service offers presented thanks to powerful communication tools.





