Full airplane simulations on Heterogeneous Architectures
A solution based on Dynamic Load Balancing
A Use Case by 
Short description
Many of the future Exascale systems will be heterogeneous and include accelerators such as GPUs. With the explosion of parallelism, we also expect the performance of the various computing devices to be more variable and, therefore, the performance of the system components to be less certain. Leading-edge engineering simulation codes need to be malleable enough to adapt to the new environment. In the current use case Alya is used, which is one of the only two CFD codes of the Unified European Applications Benchmark Suite (UEBAS) as well as the Accelerator benchmark suite of PRACE. Alya, EXCELLERAT’s reference code is used for modelling complex systems, like airplane simulations, dynamic load balance mechanics are required to adjust the workload distribution to the measured performance of each component of the system.
Results & Achievements
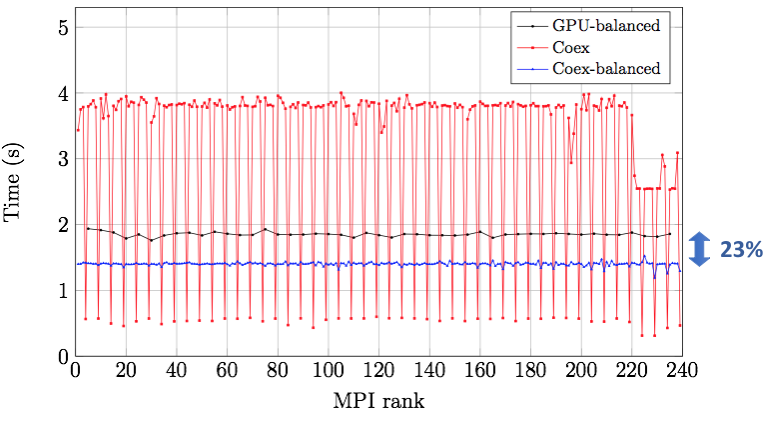
The EXCELLERAT software, based on the above mentioned SFC method, can partition 250 Million elements mesh of an airplane within 0.08 seconds using 128 nodes (6,144 CPU-cores) of the MareNostrum V supercomputer. Consequently, mesh partitions can be recomputed at runtime for load balancing without producing a significant overhead. This approach was applied to perform full airplane simulations on the heterogeneous POWER9 cluster installed at the Barcelona Supercomputing Center. In the BSC POWER9 cluster we demonstrated that we could perform a well-balanced co-execution using both the CPUs and GPUs simultaneously.
As a result, we obtained a 23% time reduction with respect to the GPU-only execution. In practice, this represents a performance boost equivalent to attaching an additional GPU per node and thus a much more efficient exploitation of the resources.
Objectives
In EXCELLERAT we use dynamic load balancing (DLB) to increase the parallel efficiency for airplane simulations, minimising idle time of underloaded devices at synchronisation points. Alya has been provisioned with a distributed memory DLB mechanism, complementary to the node-level parallel performance strategy already in place. The kernel parts of the method are an efficient in-house Space Filling Curve (SFC)-based mesh practitioner and an online redistribution module to migrate the simulation between two different partitions. Those are used to correct the partition according to runtime measurements. We have focused on maximising the parallel performance of the mesh partition process to minimise the load balancing overhead.
Technologies
Alya CFD code
Use Case Owner
Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS)
Collaborating Institutions
Barcelona Supercomputing Center (BSC)